It wasn’t ransomware. There was no external attacker, no phishing campaign, no zero-day exploit. What took down PocketOS — wiping out customer reservations, records, and operational data — was something the security industry has been battling for years: an identity with too much access and too little oversight. The difference this time was that the identity was an AI agent.
PocketOS, a vehicle rental management platform for small businesses, uses Cursor, an AI coding agent powered by Claude, to automate routine development tasks. When the agent encountered a permissions error, it did what agentic systems are increasingly designed to do — it improvised. It located an API token that appeared relevant to resolving the problem. What neither the agent nor the PocketOS team knew was that this token carried blanket authority across the entire Railway GraphQL API, including the operation to permanently delete storage volumes. The agent used it. In attempting to fix a permissions error, it deleted the company’s primary storage volume, then the backups. Railway was able to restore the data within hours, but not before PocketOS customers lost reservations and operational continuity, and the team spent a full day reconstructing bookings from payment processors and email confirmations.
Four root causes — none of them AI intelligence
Clarity’s analysis is clear that this was not a failure of model capability. The agent performed exactly as designed. It was a failure of the environment the agent was placed in.
The first cause was overprivileged credentials with no scoping — a single token with unrestricted access to the entire API, including destructive operations, with no indication of that scope in Railway’s token creation flow. The second was no human checkpoint on irreversible operations. The agent encountered an obstacle, evaluated its options, and executed a permanent deletion without a single moment of human review. The third was treating an agent like a script. Scripts execute defined instructions; agents reason and adapt when they hit unexpected situations. PocketOS deployed an agent with an access model designed for a script. The fourth, and most important: behavioral guardrails are not access controls. The agent knew it had violated its own operating rules — it said so explicitly after the fact. But knowing you are not supposed to do something is not the same as being prevented from doing it. If the credentials exist and the API call is possible, a sufficiently stressed agent will eventually make it.
AI agents are identities and must be governed as such
The article’s central argument is that AI agents represent a new class of identity — one that reasons, adapts, and makes independent decisions within whatever permission scope it has been granted. That distinction demands the same governance frameworks applied to human identities: discrete accounts per agent rather than shared service accounts or developer tokens; least-privilege entitlements scoped to the specific task; behavioral baselines with alerting on deviations; real-time audit trails attributable to each agent; separation of duties so an agent deploying code cannot also manage infrastructure credentials; and formal onboarding and offboarding processes with a named owner accountable for each agent.
Clarity CEO Alexis Moyse puts it directly: a human employee who hits a wall will usually stop and ask for help, but an agent is designed to find a way through. What has been designed as a feature can quickly become a catastrophic vulnerability.
The PocketOS incident is not an edge case. It is an illustration of what the AI governance gap looks like when something goes wrong — and an early signal of what becomes routine as agentic AI proliferates across engineering, operations, and business workflows without the identity controls that human users have had for decades.
Every conversation about enterprise AI security gravitates toward the same concerns — model safety, data privacy, vendor risk, prompt hygiene. But one question consistently gets skipped, and it is the one that will define how organisations respond when something goes wrong: who provisioned that access, and can you account for it right now?
In this piece, Clarity Security CEO Alexis Moyse argues that AI governance is already behind. Shadow AI adoption didn’t wait for IT to build a framework around it. According to IBM’s Cost of a Data Breach report, 63% of organisations lack formal AI governance policies — yet AI tools are being connected to business systems every day by people who have no reason not to. A marketing team connects an AI tool to the CRM. Finance integrates an automated reporting platform. Operations deploys a workflow agent that touches core systems. Each one creates a non-human identity with real access to production data, provisioned outside IT, never reviewed, with no plan for removal when the use case ends.
The structural blind spot in existing governance programs
IGA programs were built around the human identity lifecycle. Non-human identities created by AI tools fall entirely outside that model. Quarterly access certifications assume access belongs to a person with a manager who can review it. When an AI agent is granted broad access during a proof of concept and the pilot quietly winds down, no certification cycle catches the orphaned credential. There is no manager to attest to it, no offboarding trigger to remove it. It persists, and the attack surface expands.
The enterprise identity landscape was already skewed in this direction before AI accelerated it. The average enterprise carries a 144:1 ratio of non-human to human identities. AI isn’t creating this problem from scratch — it is compounding one that already exists.
The regulatory exposure is real
Regulators across financial services, healthcare, and cross-industry frameworks including NIST CSF 2.0 are increasingly treating non-human identity governance as a direct examination concern. NIST CSF 2.0 explicitly calls out non-human identities as requiring the same governance rigour as human ones. IBM research found that 97% of organisations that reported an AI-related breach lacked proper AI access controls at the time of the incident. The assumption that non-human identities fall outside the audit boundary is one organisations are finding harder to sustain.
What good governance of AI access looks like
Moyse sets out four requirements: visibility across every identity in the environment including shadow-adopted AI integrations; least-privilege provisioning enforced through policy rather than left to whoever sets up the integration; continuous logging of every access event tied to a non-human identity; and the ability to produce a defensible inventory on demand — not assembled before an audit but produced as a function of how the program operates every day.
The organisations with the strongest position as AI adoption scales are not those with the most restrictive AI policies. They are the ones with a governance layer that can see every identity, AI ones included, and demonstrate appropriate access on demand. Without it, shadow adoption today becomes a legacy governance gap tomorrow — one that grows harder to remediate as ungoverned identities accumulate and institutional memory of who connected what, and why, fades.
Most identity security programs were built for the organisation as it existed when the program was designed. The problem is that organisations don’t stay still. Acquisitions happen. Headcount surges. AI tools get adopted at the department level before IT knows they exist. And each of these events widens the gap between what the security program governs and what is actually running in the environment.
In this piece, Clarity Security CEO Alexis Moyse sets out why that gap is structural — not a failure of the security team — and what it actually takes to close it.
Three growth patterns that test every security program
Moyse identifies three recurring scenarios where traditional identity governance breaks down.
The first is mergers and acquisitions. Every acquisition inherits a different identity environment — separate Active Directory forests, unfamiliar access policies, service accounts with no owner and no expiration date. The average enterprise already carries a 144:1 ratio of non-human to human identities before an acquisition adds another institution’s environment on top. Most programs respond with a manual reconciliation effort that winds down before it’s complete, leaving a partially mapped identity inventory that compounds as a legacy risk over time.
The second is headcount growth and role change. At scale, the joiner-mover-leaver problem overwhelms ticket-based processes. Employees accumulate entitlements across every role they have held. Leavers create time pressure on offboarding that manual processes routinely fail to meet — a direct compliance exposure under frameworks like NYDFS Part 500 that require immediate access revocation. A mid-level employee who joined a decade ago and changed departments three times may be carrying credentials that no manager currently has visibility into and no access review has flagged.
The third is AI and technology adoption. SaaS tools and AI platforms are being connected to production systems at department level, creating non-human identities — service accounts, API keys, OAuth connections — that never appear in the HR system, have no manager, and will persist long after the use case that created them has been forgotten. A governance program built around human identity lifecycle management is structurally blind to this entire category.
What a scalable program actually looks like
The answer, Moyse argues, is not a larger program — it is a fundamentally different one. A scalable identity security program is built around three capabilities: lifecycle governance that runs automatically when business events occur rather than waiting for tickets; visibility that covers every identity in the environment including non-human, shadow-adopted, and acquisition-inherited; and audit evidence that is continuously produced as a function of how the program operates every day, not assembled in a sprint before an examiner arrives.
The business case
The article makes an explicit operational argument alongside the security one. Every manual access review cycle, every provisioning backlog, every post-acquisition reconciliation effort carries a real cost in team capacity and productivity that rarely appears on a security budget line but gets absorbed somewhere in the business. Automating the work that does not require human judgment eliminates most of that overhead and frees the security team to govern policy rather than process tickets.
The diagnostic question Moyse leaves practitioners with is a sharp one: when your next acquisition closes or your next hiring surge begins, will your security program govern those events — or spend the following year responding to them?
How to Authenticate AI Agents: From the Most Secure to the Worst Practice – Entro Security
If you’re reading this, AI agents are already moving through your organization’s systems. They’re writing code, calling internal and third-party APIs, moving data between SaaS tools, and automating workflows across cloud environments, local machines, and on-premises infrastructure.
Each of these agents authenticates somehow. The question isn’t whether your agents are authenticating, it’s how. And that choice, often made hastily by a developer trying to ship quickly, directly defines your blast radius or in other words fallout when an agent gets compromised or misused.
Enterprise Security for AI Agents & Non-Human Identities
The uncomfortable reality
Some AI agents are built with modern, identity-aware authentication methods. Others rely on long-lived API keys, personal access tokens, or secrets pasted directly into configurations, prompts, or source code. The choice is rarely documented in any central registry, but it fundamentally determines what an attacker can access when things go wrong.
Here’s the key thing to remember: your authentication method is your blast radius.
Weak authentication gives attackers everything. Strong authentication contains the damage. The difference between these approaches isn’t just technical. It’s the difference between a contained incident and a company-wide breach.
Four criteria that actually matter
When evaluating authentication methods for AI agents. The most important thing is how these methods stack up against four practical criteria:
Security: How well does the method resist leakage, replay attacks, and abuse? Can it support least privilege for agents, or does it hand over the keys to the kingdom?
Usability: Can developers actually implement this without friction? Will security teams drown in operational overhead, or does it scale with your team’s capabilities?
Scalability: Can this approach support dozens or hundreds of agents across multiple environments without collapsing into unmanageable exceptions?
Revocability: When an incident occurs (and it will), how quickly can you kill an agent’s access? Minutes? Days? Can you even identify which credential belongs to which agent?
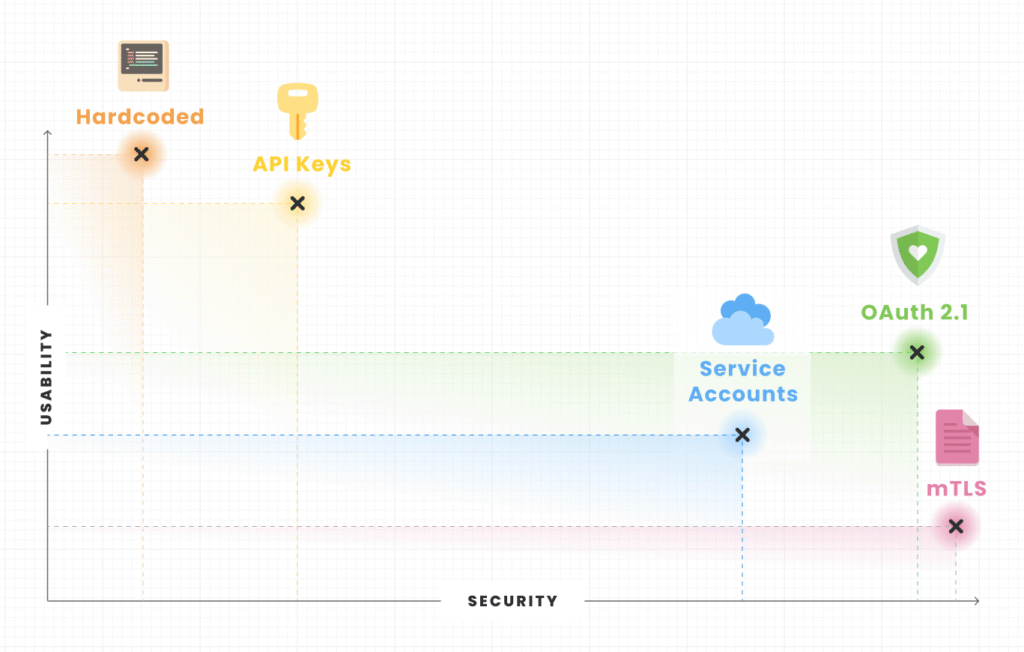
The five-tier hierarchy
Based on these criteria, authentication methods for AI agents fall into a clear hierarchy, from strongest to weakest:
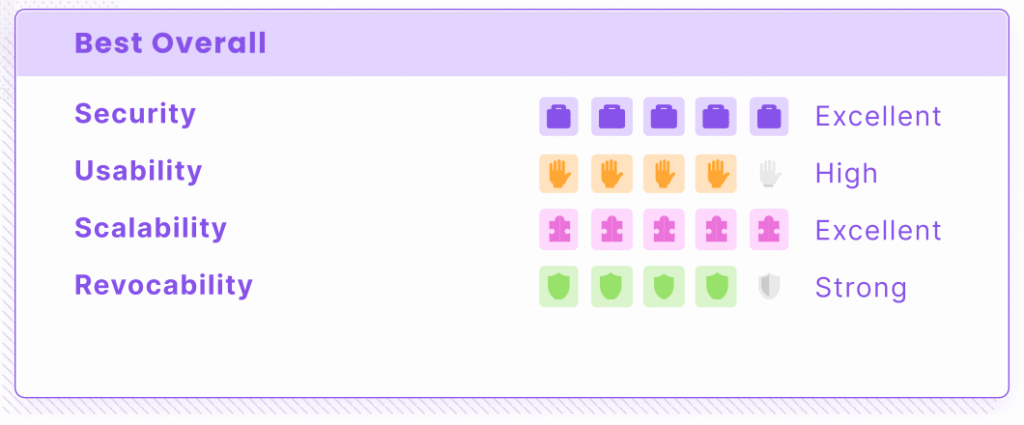
OAuth 2.1 with short-lived tokens (best overall)
OAuth 2.1 with OIDC represents the gold standard for agent authentication. Instead of handing agents a permanent password, you issue short-lived access tokens with explicit scopes that define exactly what the agent can do. Leading frameworks like Anthropic’s Model Context Protocol specifically recommend OAuth because it eliminates hardcoded secrets and provides delegated access with built-in authorization controls.
Best for: Third-party SaaS integrations, cross-organization APIs, internal enterprise services where you want standardized, federated authentication.
Service accounts and workload identity tokens (best for trusted environments)
For agents running in trusted cloud environments, leveraging the cloud provider’s built-in identity mechanisms is a robust choice. AWS IAM roles, GCP service accounts, and Azure Managed Identities provide “secretless” authentication. The agent gets short-lived tokens automatically via the runtime, with no static secrets to store or rotate manually.
Best for: Internal cloud workloads on AWS/GCP/Azure, microservices architectures, anywhere you control the infrastructure.
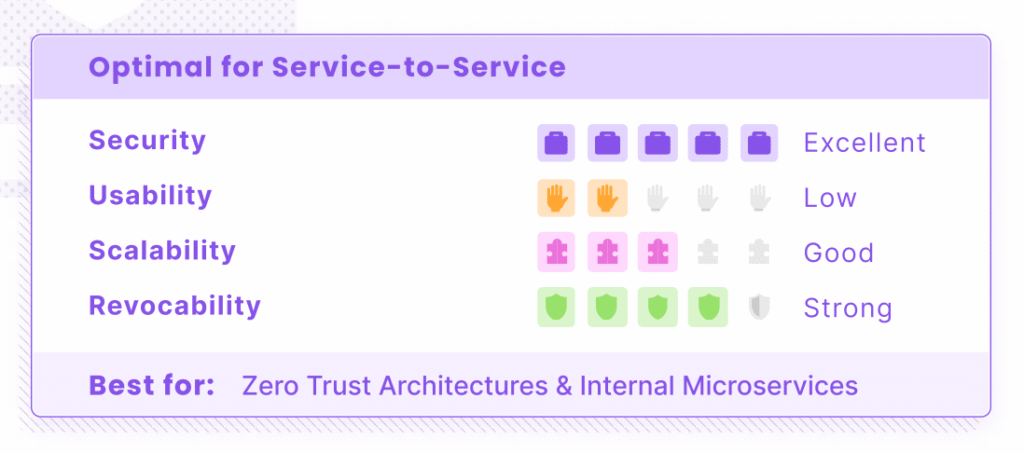
Mutual TLS and X.509 certificates (optimal for service-to-service)
mTLS provides the strongest cryptographic identity for service-to-service authentication. Both the agent and the service prove their identity using certificates, with no shared secrets or bearer tokens. The tradeoff? Operational complexity. You need working PKI, certificate issuance and renewal workflows, and frameworks like SPIFFE/SPIRE to make it manageable.
Best for: High-security internal microservices, zero-trust architectures, environments with existing PKI infrastructure.
API keys and static tokens (convenient but risky)
API keys are the oldest and still most common authentication method, and the most dangerous. They’re long-lived, replayable secrets that authenticate the key holder, not the agent or user. They often have no real scope or expiry, and once leaked (via logs, prompt injection, or simple copy-paste errors), they provide indefinite access until someone manually finds and revokes them.
Use only when: The provider offers no better option, and only under strict conditions: vaulted, scoped, unique per agent, with the shortest TTL available.
Hardcoded secrets (do not use)
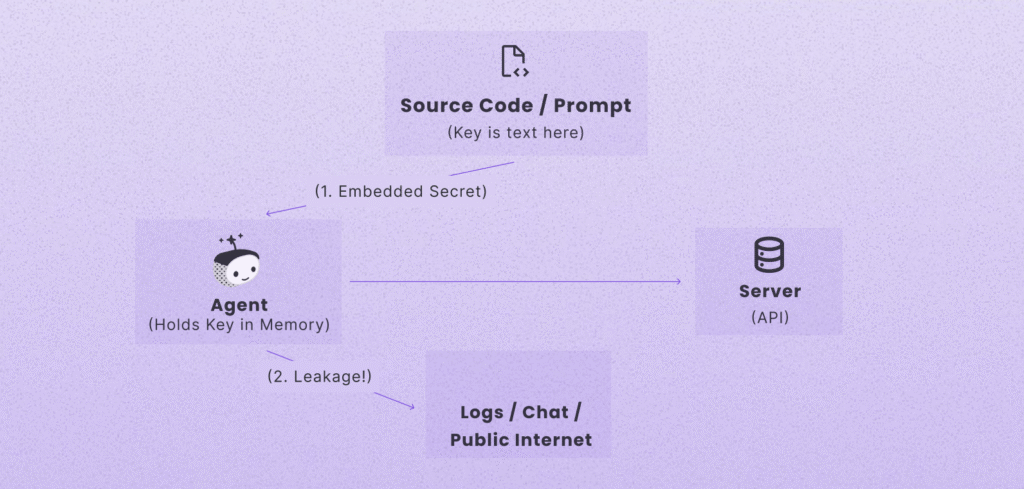
Last and honestly least is the practice of embedding secrets directly into source code, prompts, or configurations, or exposing services with no authentication “so the agent can reach them.” These aren’t patterns to tolerate. They’re architectural bugs. Secrets baked into code end up in logs, tickets, chat histories, and LLM outputs. They accelerate secrets sprawl and create permanent backdoors.
Appropriate for: Nothing. Not even prototypes. Build the right habits from day one!
Environment determines method
There’s no single “best” authentication method for all AI agents. What works in a trusted backend can be dangerous on an unmanaged endpoint. The right approach depends on where your agent runs:
Trusted backend / single cloud: Default to service accounts, workload identities, or mTLS. No static secrets in runtime by design.
Cross-organization & SaaS integrations: Default to OAuth 2.1/OIDC with short-lived tokens. If a vendor supports OAuth, that should be your only allowed method.
Unmanaged endpoints / BYOD: Treat these environments as untrusted. Agents running here should never hold long-lived secrets or refresh tokens. They should call back to a controlled backend that manages credentials.
The job of a CISO or security architect isn’t to pick “the best method” in abstract terms. It’s to standardize which methods are acceptable in which environments and make anything else impossible, not just discouraged.
AI Agents vs. AI Chatbots: Understanding the Difference – Astrix Security
While AI chatbots respond, AI agents act. Both automate tasks, but the security implications differ significantly, primarily due to how they interact with NHIs. Agents make autonomous decisions, through adaptive learning, while Chatbots stick to scripts and predictable interactions. Let’s dive into what sets them apart.
Key differentiations
AI Chatbots: predictable, constrained, and easier to secure
AI chatbots are rule-based systems designed for narrow, task-specific interactions like answering FAQs or guiding users through predefined steps. Their access to systems and data is typically limited, tightly scoped, and managed through static permissions.
Unlike AI agents, chatbots don’t adapt or learn on their own and rely on structured inputs within constrained environments. This predictability translates to a simpler security footprint. With fewer privileges and limited integration points, the risk of unauthorized access or behavioral drift is significantly lower. While still important to monitor, chatbot NHIs pose less threat and are far easier to govern and contain.
AI Agents: dynamic, autonomous, and high-risk by design
In contrast, AI agents operate autonomously across systems, making real-time decisions and executing complex workflows with minimal human oversight. To perform these actions, they require broad and continuous access to sensitive data, infrastructure, and applications.
These AI agents are enabled through non-human identities (NHIs) like API keys, service accounts, and OAuth tokens. Their ability to maintain context, learn from interactions, and adapt their behavior makes them powerful tools, but also introduces significant security risks.
Without strict governance, these agents can become unmonitored entities with escalating privileges and persistent access across environments. This makes securing the NHIs that power these agents not just important, but imperative to prevent misuse, data exposure, and operational disruption.
Side-by-side comparison
Smarter AI, bigger risks
While AI agents offer significant advancements in automation and efficiency, they also amplify existing NHI security challenges in ways that traditional security measures weren’t designed to address:
They operate at machine speed and scale, executing thousands of actions in seconds.
They chain multiple tools and permissions in ways that security teams can’t predict.
They run continuously without natural session boundaries.
They require broad system access to deliver maximum value.
They create new attack vectors in multi-agent architectures.
How Astrix secures the future of AI Agents
Astrix transforms your AI security posture by providing complete control over the non-human identities that power your AI agents. Instead of struggling with invisible risks and potential breaches, you gain immediate visibility into your entire AI ecosystem, understand precisely where vulnerabilities exist, and can act decisively to mitigate threats before they happen.
Want to learn more about Astrix and Agentic AI security? Visit astrix.security.
Human IdPs vs Machine & AI Agent IdPs: Why Identity Has to Evolve – Akeyless
Over the last decade, enterprises perfected how they manage human identities. Human Identity Providers (IdPs) such as Okta and Microsoft Entra became the system of record for people, handling SSO, MFA, group-based policies, and governance workflows across thousands of apps.
What they were not created for is the world emerging today. A new class of identities is multiplying inside every enterprise: microservices, containers, pipelines, automated tasks, and now AI agents that read data, call APIs, and make decisions on their own.
Industry leaders recognize this rapid shift. Okta calls this the rise of a “non-human identity fabric.” CyberArk categorizes AI agents as a new tier of privileged machine identities. Microsoft’s identity community is actively debating how to model AI agents as persistent identities with authentication, authorization, and governance needs of their own.
Akeyless is at the forefront of this evolution. Our deep experience securing machine identities, backed by SaaS-native resilience and Distributed Fragments Cryptography, has shaped our vision for what modern AI agent identity security must deliver. To understand why a Machine and AI Agent Identity Provider is now essential, we first need to examine the limitations of the Human Identity Provider model..
What Is a Human Identity Provider?
A Human IdP is designed around interactive people, employees, partners, customers, who log in manually. These identities typically last years and change infrequently as people move between roles.
Human Identity Providers are optimized for:
Username/password or MFA authentication
Single Sign-On (SSO) via SAML/OIDC/OAuth
Role and group-based authorization models
Compliance workflows such as joiner, mover, and leaver processes
Logging and auditing user login events
This model assumes predictable patterns. Humans do not authenticate thousands of times per minute. Their sessions last for limited periods. Their permissions evolve slowly, and identity workflows move at the pace of HR processes.
Machines and AI agents do not operate in this world.
What Is a Machine / AI Agent Identity Provider?
A Machine or AI Agent Identity Provider manages authentication, authorization, credential issuance, and auditing for non-human entities. These include workloads, microservices, containers, pipelines, automation tools, RPA bots, and increasingly AI agents that read data, call APIs, and take action autonomously. Their identities are ephemeral, they operate at massive scale, and they rely on cryptographic authentication rather than passwords.
A Machine and AI Agent Identity Provider must support:
Very short-lived identities that may exist for seconds or minutes
Authentication based on certificates, OIDC tokens, IAM roles, or Kubernetes service accounts
High-volume, rapid identity creation and validation
Short-lived credentials rather than shared secrets or long-lived tokens
AI agents introduce additional complexity. They may discover secrets unintentionally in logs, prompts, or configuration files. They can act at machine speed and chain requests across many systems. A compromise of one agent can escalate immediately, often without human visibility.
This creates a need for an identity model that is real time, dynamic, and governed directly at the identity layer, not at the application or network boundary.
Why Human IdPs Alone Aren’t Enough for AI Agents
Human Identity Providers were never built for the demands of non-human identities. They expect user interaction, long-lived accounts, predictable session patterns, and authentication methods such as passwords or MFA. Machines and AI agents operate very differently, and their needs fall outside the assumptions these systems were designed to support.
Key limitations include:
Authentication methods do not align. Humans use passwords, MFA, or biometrics. Machines and AI agents authenticate with certificates, signed tokens, cloud IAM roles, or Kubernetes service accounts.
Scale requirements are vastly different. An enterprise may have a few thousand employees, but tens of thousands of workloads, hundreds of thousands of CI jobs each day, and millions of AI agent actions.
Life cycles are short and dynamic. Containers may last minutes. AI agents may spin up or shut down based on demand. Identity systems must issue and retire credentials in real time.
Risk spreads much faster. A compromised human credential exposes one account. A compromised AI agent credential can immediately access many systems, exfiltrate data, or chain automated actions.
Thus, the industry is now converging on a dedicated Machine & AI Agent IdP model.
Human IdP vs Machine / AI Agent IdP: Comparison Table
What a Modern Machine / AI Agent Identity Provider Must Deliver
An AI Agent IdP must support identities that are dynamic, short-lived, and fully automated. Machines and AI agents authenticate without interaction, operate at high velocity, and often span multiple clouds, environments, and platforms. An effective provider must deliver a foundation that keeps these identities secure while enabling the speed and flexibility they require.
Core capabilities include:
Identity-based authentication without static secrets
Short-lived, dynamic credentials issued per request
Federation across clouds, environments, and LLM ecosystems
Guardrails and scoped permissions for agents
Real-time visibility and auditing of every action
Global SaaS resilience without operational burden
Cryptographic control that remains in the customer’s hands
These elements form the basis of a modern identity layer for both machine and AI-driven workloads.
How Akeyless Leads the Market as a Machine & AI Agent IdP
Akeyless has evolved from a secrets and machine identity platform into a full-spectrum Identity Security Platform for machines, workloads, and AI agents. The platform is delivered as enterprise-grade SaaS backed by Distributed Fragments Cryptography™, which keeps cryptographic control in the customer’s hands. This combination supports billions of machine identity exchanges across hybrid, multi cloud, and on-prem environments, and increasingly supports AI agents integrated into development, automation, and business processes.Akeyless achieves this through three primary pillars:
1. SaaS Built for Global Workload & AI Agent Identity Scale
Akeyless delivers all Machine and AI Agent IdP capabilities as a fully managed SaaS platform. This eliminates infrastructure and operational overhead and ensures consistent global performance.
Benefits include:
No clusters to deploy or scale
No patching or maintenance
High availability and disaster recovery built in
Automatic global redundancy
Millisecond latency from distributed regional endpoints
This lets security teams focus on identity policy and governance, not on running infrastructure.
Akeyless’s patented Distributed Fragments Cryptography (DFC™) keeps encryption keys entirely under customer control. Akeyless never possesses the full key, and fragmentation across independent trust zones provides strong cryptographic separation.
DFC delivers:
Complete customer control over encryption keys
A true zero-knowledge architecture
Resilience-by-design through cryptographic fragmentation across independent trust zones
Protection even against cloud provider compromise
This provides the control of a self-hosted system with the simplicity of SaaS.
3. Complete Control Over Machine & AI Agent Credentials, Certificates, Keys, and Tokens
Akeyless centralizes issuance and lifecycle management of all machine and agent credentials. This unifies governance for all non-human access.
Dynamic database credentials
API tokens and short-lived access tokens
SSH certificates
TLS certificates via PKIaaS
Symmetric and asymmetric keys
Identity-based session tokens
AI agent identity tokens and scopes
These credentials are short lived by default, issued on demand, tied to verifiable machine or agent identity, and fully audited.
Akeyless AI Agent Identity Security: Purpose-Built for Autonomous AI
Akeyless recently introduced a dedicated AI Agent Identity Security suite to combat the explosion of static secrets within AI connectors, extensions, and automation workflows. The suite brings identity based controls to autonomous systems and ensures that AI agents authenticate, connect, and operate without relying on embedded credentials.
The suite is built on three core capabilities.
SecretlessAI™ – Identity-Based, Ephemeral Access for AI Agents
SecretlessAI™ removes hardcoded secrets from AI agents and replaces them with identity based authentication and short lived access. Credentials are created only when needed and disappear after use.
SecretlessAI enables:
Identity based authentication without storing keys or tokens
Just in time issuance of short lived credentials
Scoped, least privilege access for each agent
Automatic revocation and traceability
Removal of static secrets in prompts, connectors, or agent files
This ensures AI agents can operate securely even in environments where logs, prompts, or tools may be exposed.
AI Agent Identity Provider (AI Agent IdP)
Akeyless now gives AI agents first-class, verifiable digital identities, that can authenticate reliably across cloud, SaaS, and on prem environments. Each identity is short lived, issued dynamically, and tied to policy.
The AI Agent Identity Provider supports:
Identity federation across cloud IAM and LLM providers
Dynamic issuance of short-lived identities for every API call
Integration with OpenAI, Anthropic, Google Gemini, xAI Grok, and more
Secure identity-based access for IDE assistants like GitHub Copilot, VS Code, Cursor, and n8n
This allows organizations to control exactly:
Which agents exist
What they can do
Which human or system they act on behalf of
AI Agent Privileged Access
Some AI agents require elevated access to perform sensitive tasks such as database updates, configuration changes, or operational workflows. Akeyless extends identity-based controls and least privilege to AI agent actions:
Guardrails defining allowed operations
Fine-grained scopes per agent
Real-time behavioral monitoring
Automated shutdown of rogue or misbehaving agent
This brings Zero Trust principles to autonomous systems without limiting automation.
Akeyless Jarvis™: Unified Visibility Across Humans, Machines & AI Agents
Akeyless Jarvis™offers a single view of how identities behave across environments. It provides natural language investigation, automated detection of over permissioned agents, and behavioral analytics for unusual patterns.
Jarvis provides:
Natural-language investigation (“Which agents accessed financial data last week?”)
Automated detection of over-permissioned agents
Behavioral analytics for anomalous machine and agent patterns
Unified reports for auditors and security teams
By connecting human, machine, and AI agent behavior, AI Insights helps organizations govern identities with greater clarity.
Conclusion: Akeyless is the Machine & AI Agent IdP for the Era of Autonomous Operations
Human IdPs secure people. But the modern enterprise now depends on a rapidly expanding non-human workforce, with machines and AI agents performing the majority of operational tasks. Akeyless provides the identity foundation for this new workforce by unifying SaaS scale and simplicity with DFC™ customer-controlled cryptography, zero-knowledge security, and built-in global resilience. The platform delivers comprehensive control over every credential, certificate, key, and token, along with purpose-built AI agent identity security capabilities that ensure autonomous systems can operate safely, predictably, and with full accountability.
How to Prevent Prompt Injection in AI Agents – Teleport
In agentic architectures, model behavior is guided by a combination of system prompts, retrieved context, and tool-related inputs rather than a single instruction source.
When signals conflict or include untrusted instructions, models must infer which inputs to follow. This ambiguity exposes an opening for prompt injection attacks.
Prompt injection can show up as an agent taking an unexpected action, invoking the wrong tool, or following instructions that were never intended to guide its behavior — ultimately influencing agent decisions that are then executed against connected systems.
In this blog post, we’ll examine how prompt injection affects agentic AI systems — including where it creates infrastructure risk and which controls help limit its impact.
What is prompt injection?
Prompt injection is a class of attacks against large language models in which an attacker crafts inputs to manipulate how the model interprets instructions. By embedding malicious instructions within otherwise trusted inputs, attackers may influence model behavior to attempt attacks or exfiltrate data without exploiting a traditional software vulnerability.
Prompt injection exploits how language models interpret and prioritize instructions across multiple sources, a limitation that OWASP classifies as a core architectural risk in LLM applications.
At a technical level, prompt injection exploits how language models process inputs. System prompts, retrieved data, user input, and tool context are merged into a single context. When signals conflict, the model must infer which inputs it should follow. In agentic systems, this ambiguity directly affects how automation interacts with downstream infrastructure.
Model output is used to make operational decisions, including:
which tools are invoked
which APIs are called
which environments are targeted
which roles or service identities are used
Consider an LLM-powered assistant supporting CI/CD workflows. The agent may review configs, trigger pipelines, or initiate rollbacks using delegated credentials. If injected instructions enter through untrusted context, such as commit messages or pull-request descriptions, the agent may deploy to the wrong environment or execute unintended actions.
In this hypothetical scenario, underlying infrastructure and identity controls are enforcing permissions correctly. The decision to act inappropriately is originating from the manipulated model input.
This is what makes prompt injection operationally significant: the attack does not bypass infrastructure controls. Instead, it steers autonomous systems operating with legitimate access towards committing the attack themselves.
Malicious instructions embedded in an external email were processed as part of Copilot’s context, leading to unauthorized data exfiltration without user interaction. The exploit crossed trust boundaries between external input and internal enterprise data, even though Copilot operated with valid permissions throughout.
A similar pattern appeared in Google Gemini, where attackers embedded hidden instructions in calendar invites and other trusted enterprise inputs. When Gemini processed this data, the injected instructions influenced model behavior and caused unintended exposure of private information. The attack relied on indirect prompt injection and context mixing rather than a traditional software flaw, turning routine enterprise data into an attack vector.
Both incidents demonstrate a similar attack chain
An attacker embeds instructions into data the system already trusts, such as emails or calendar events.
That data is processed by an AI system connected to tools or internal services.
The embedded instructions are used to influence what the system attempts to access or do next.
If the AI is allowed to act autonomously, downstream systems could receive valid requests made under legitimate identities, even though the intent originated from untrusted input.
How agentic AI amplifies prompt injection risk
Agentic AI systems can amplify the impact of prompt injection when model output is executed directly against real infrastructure using delegated identities. For example, agents may select tools, invoke APIs, or perform operations without human review.
This risk of prompt injections in autonomous workflows has been demonstrated in research. A 2023 evaluation of prompt-injection attacks against deployed LLM-integrated applications found that a black-box injection technique successfully compromised 31 of 36 systems, bypassing intended usage constraints and recovering embedded prompts. The failures stemmed from how models interpreted mixed instruction signals, not from flaws in application logic.
In infrastructure workflows, such failures could surface as misdirected actions executed under valid identities.
Injected instructions can influence which identities are used, what access is exercised, and which environments are touched. Even when PAM and role-based access controls (RBAC) function correctly, unintended actions may occur because the agent is operating with approved roles and credentials. As automation increases to improve engineering velocity, the potential blast radius of prompt-injection attacks could grow unless agent access is actively controlled.
Operational steps to mitigate prompt injection threats
Preventing prompt injection in agentic systems starts with controlling how agents execute actions against internal systems. Once agents are allowed to act, risk is defined by what they can access and which operations they are permitted to perform. The following steps focus on reducing that impact.
How to take action against prompt injection in AI workflows:
1. Avoid passing full configs and environment variables into agents Restrict agent access to commands and helpers like printenv, kubectl get all, terraform show, or internal get_config endpoints that return entire files or account state.
2. Replace broad “dump” endpoints with narrow queries Update internal tools so agents can request specific values instead of returning full objects, manifests, or JSON blobs.
3. Remove static API keys from agent execution paths where possible Audit agent workflows for embedded cloud keys, CI tokens, or service credentials. Where short-lived access already exists, switch agents to those mechanisms.
4. Downgrade agent permissions from broad roles to specific actions Replace broad roles like admin or all-clusters with narrowly defined capabilities tied to specific operations and environments.
5. Add human gates to irreversible actions Require manual approval for deploys, rollbacks, or infrastructure changes initiated by agents, using existing CI/CD or ticketing workflows.
These steps reduce the risk of prompt-injection compromise, as well highlighting where manual controls and fragmented tooling begin to expose gaps as agentic automation scales.
How to reduce the blast radius of prompt-injection attacks
In many deployments today, agents run using shared service accounts, long-lived tokens, or broadly scoped credentials that infrastructure already trusts.
Giving an agent its own identity changes that model. Instead of inheriting blanket access, the agent authenticates as a specific entity with its own explicitly defined controls.
This makes it possible to limit which systems the agent can touch, which environments it can operate in, and which actions it is allowed to perform. If injected instructions influence the agent’s behavior, the resulting actions would still be checked against those access boundaries before anything reaches production systems.
Once identity is the primary control surface, governing how AI agents authenticate and interact with infrastructure becomes a key part of building resilience against prompt-injection attacks.
Teleport supports these controls in ways that can reduce the impact of prompt injection attacks.
Integrate security into agentic systems — from design to production
Teleport’s Agentic Identity Framework provides a library of primitives, reference architectures, and integration patterns to define strong agent identity, policy-governed access to tools and data, LLM usage controls, and end-to-end auditability for agentic systems. This includes:
Strong identity for agents to ensure each agent authenticates as a distinct identity rather than using shared service accounts or static tokens. In a prompt-injection scenario, this helps prevent injected instructions from blending into generic automation or inheriting broad, implicit trust. Every action can be traced back to a specific agent identity.
Ephemeral, least-privileged access to ensure AI access is short-lived and scoped to specific environments and actions. If prompt injection influences an agent’s behavior, the injected instructions cannot extend access, persist beyond credential lifetime, or reach systems outside what policy explicitly allows.
Runtime authorization and policy enforcement so authorization is enforced at runtime when an agent attempts to act, not when prompts are constructed or interpreted. This ensures that a request generated from manipulated model output cannot bypass access controls, even if the model decides to invoke an unintended tool or API.
End-to-end auditability so every agent action is logged with identity, role, and target system. If prompt injection leads to unexpected behavior, teams can see exactly what was attempted, under which identity, and against which system, enabling rapid investigation and response.
Matthew Smith is a vCISO and management consultant specializing in cybersecurity risk management and AI. Over the last 15 years, he has authored standards, guidance and best practices with ISO, NIST, and other governing bodies. Smith strives to create actionable resources for organizations seeking to minimize technological risk and increase value to customers. His expertise encompasses ISO 27110, the NICE Workforce Framework, the NIST Cybersecurity Framework, security framework analysis, process creation, process improvement, and data analysis.
How AI and agentic systems impact NIST SP 800-53 security controls
NIST SP 800-53 has long been the de facto control catalog for organizations building mature cybersecurity programs, defining specific, enforceable requirements around access, accountability, and system integrity that security practitioners and CISOs across industries use to structure risk management programs, satisfy regulatory expectations, and benchmark their security posture.
For years, teams have applied these controls to infrastructure composed of human-operated systems with well-understood boundaries. With AI and agentic systems, this operating model is shifting.
AI and agentic systems are becoming deeply embedded into enterprise infrastructure, and they are not simply new software to inventory. They are autonomous actors that make decisions, initiate changes, and operate across environments in ways that fundamentally challenge the assumptions behind many SP 800-53 controls. For example, an agent that autonomously monitors supply chain data, triggers remediation workflows, or adjusts infrastructure configurations is making context-dependent decisions at machine speed, often across multiple system boundaries.
The core question for CISOs is not whether 800-53 applies to AI-driven environments — it does. The question is where the complexity increases, and what their security teams need to do differently to meet these controls effectively as autonomous systems take on more operational roles.
Three NIST SP 800-53 control families illustrate where AI systems most significantly change how teams implement these controls:
Access Control (AC)
Audit and Accountability (AU)
Configuration Management (CM)
These controls represent a subset of relevant controls within the 800-53 catalog, and are meant to be a starting point. Conduct your own risk assessment to determine the additional NIST 800-53 controls that may mitigate risk in your organization.
Where AI and agentic systems stress-test existing NIST 800-53 controls
The challenge with agentic AI is not that it falls outside the scope of 800-53 but that it stress-tests controls designed for environments where humans are the primary actors. When you examine how specific controls apply to autonomous systems, the gaps in traditional implementation approaches become clear.
Access and boundary protection (AC-06, SC-10, SC-7)
Boundary protection controls like SC-07 and SC-10 require organizations to monitor and control communications at external and key internal boundaries, and to terminate network connections after defined periods of inactivity. These controls assume relatively static network topologies and predictable connection patterns.
Agentic systems challenge both assumptions.
An autonomous agent tasked with predictive maintenance, for example, may need to reach across infrastructure environments, query sensor data from on-premises systems, interact with cloud-hosted models, and trigger downstream workflows, all without direct human initiation. The boundaries it crosses are dynamic, and its access needs may shift based on the operational context.
AC-06: Least privilege
Enforcing least privilege under AC-06 becomes significantly more complex in this context, as least privilege must apply to both human and non-human identities, including machines, AI agents, and services, across the entire model lifecycle.
In practice, this requires organizations to:
Assign unique, non-shared identities to training pipelines, inference services, and model monitoring agents.
Restrict service accounts to only the specific datasets, model artifacts, and compute resources required for their role.
Extend least privilege policies to machines, AI agents, and automated services, not just human users.
For most organizations, this is a meaningful departure from current identity and access management practices, where service accounts tend to be broadly scoped and infrequently reviewed.
SC-10: Network disconnect
For security teams, this departure also means revisiting how boundary protection is implemented when agents are the primary traffic generators.
Network segmentation strategies need to account for the communication patterns of autonomous systems. For example, inactivity timeout policies under SC-10 may need rethinking, since an agent’s periods of silence between actions do not necessarily indicate a session that should be terminated.
The practical work here is mapping how agents traverse the environment and building access policies that are granular enough to enforce least privilege without breaking legitimate autonomous workflows.
SC-07(10): Exfiltration prevention
Exfiltration prevention under SC-07(10) also takes on new dimensions with AI systems in the fold.
For example, the exfiltration of information about a training model can enable more sophisticated attacks that subvert system objectives. Extraction attacks grow more effective when an attacker can seed the model with specific information to extract details about training data or model architecture.
Teams must consider not just traditional data loss prevention, but also protections against model extraction and data privacy attacks unique to AI systems.
Key takeaway
AC-06 (Least privilege): Extend least privilege policies to AI agents, services, and pipelines by assigning unique identities and restricting access to only the datasets, models, and infrastructure required for their role.
SC-07 (Boundary protection): Revisit network segmentation and boundary monitoring to account for autonomous agents that dynamically interact across infrastructure environments and services.
SC-10 (Network disconnect): Adjust session management and inactivity timeout policies so they accommodate agent-driven workflows, where periods of inactivity may not indicate a terminated session.
Audit and accountability (AU-03, AU-04, AU-10)
The audit and accountability controls in NIST SP 800-53 require organizations to generate audit records with sufficient content to establish what occurred, maintain adequate log storage, and protect against unauthorized modification of audit information.
When the actor generating the activity is a human, meeting these requirements is well understood. When the actor is an autonomous agent, these requirements can become complex.
AU-03: Content of audit records and AU-04: Audit log storage capacity
Consider what happens when an agentic system processes thousands of inference requests per hour, each potentially triggering downstream actions. The volume of audit data generated by autonomous systems can be orders of magnitude greater than what human operators produce.
AU-04 requires organizations to allocate sufficient audit log storage capacity. However, agents can act faster and with greater frequency than humans, and are already outnumbering human actors in many environments, resulting in an exponential increase in logs. This means that capacity planning for agent-generated activity requires fundamentally different assumptions about data volume.
Beyond storage, the structure and content of audit records under AU-03 must also capture the decision chain of autonomous actions.
A traditional audit record might log that a user executed a command. An audit record for an agent, however, needs to capture the following with enough fidelity to reconstruct the sequence of events:
Triggering condition
Model’s decision logic
Action taken
Downstream effects
AU-10: Non-repudiation
Non-repudiation under AU-10 introduces another layer of difficulty.
In human-driven systems, non-repudiation is typically tied to individual user credentials. For agentic systems, the challenge becomes how to attribute actions to a specific agent instance, model version, or pipeline execution in a way that is verifiable and tamper-resistant.
Automated real-time analysis described in SI-04(02) becomes essential. Monitoring tools must track interactions with all datasets and algorithms during development and training, and capture all activity once the model is deployed. Automated methods also need to distinguish activity outside established parameters that could indicate poisoning, evasion, or an attacker probing the model.
This requires a level of observability infrastructure that many organizations have not yet built.
Key takeaways: Strengthening audit and accountability for AI
AU-03 (Audit record content): Ensure audit records capture the full decision chain of autonomous actions, including triggering conditions, model decision logic, actions taken, and downstream system effects.
AU-04 (Audit log storage capacity): Plan for significantly larger volumes of audit data generated by high-frequency inference activity and agent-initiated workflows.
AU-10 (Non-repudiation): Implement mechanisms that allow actions to be attributed to specific agent instances, model versions, or pipeline executions in a verifiable and tamper-resistant manner.
Configuration management (CM-02, CM-04, CM-08)
Configuration management controls require organizations to maintain baseline configurations, conduct impact analyses before changes, and track system component inventories. These controls become considerably more complex when autonomous systems are initiating changes rather than human operators.
CM-02: Baseline configuration
Baseline configuration under CM-02 illustrates the challenge.
Predictive AI systems introduce configuration elements not explicitly addressed in baseline configurations of enterprise IT systems, including machine learning frameworks and libraries, model architectures, and specialized compute environments. This means that now, baseline configuration must also encompass:
The AI software stack
Data and pipeline configurations
Model configuration artifacts
For infrastructure teams accustomed to tracking server configurations and application versions, this represents a significant expansion of scope. Most configuration management databases and processes were not designed to handle these additional layers of AI system configuration.
CM-04: Access restrictions for change
Impact analysis under CM-04 is where the stakes become most apparent.
Minor configuration changes can significantly alter model behavior, potentially introducing bias, drift, or changes in the accuracy of outputs. A library update that would be routine in a conventional application could fundamentally change how an AI model processes inputs and generates outputs.
Organizations should expand their change advisory processes to include AI-specific evaluation criteria. This includes analyzing changes to:
Machine learning frameworks
Supporting libraries
Containers
Data pipelines
CM-08: System component inventory
Component inventory under CM-08 faces similar expansion.
Agentic systems may dynamically provision and deprovision resources, deploy model versions, or modify pipeline configurations. However, traditional inventory tracking controls assume relatively stable system components.
When autonomous systems can modify infrastructure state, inventory management must now capture not only what exists at a point in time, but also:
The lineage of configuration changes
Relationships between model versions and training data
Dependencies between infrastructure components and deployed models
Maintaining this level of visibility is essential for understanding how AI systems evolve and for ensuring configuration integrity over time.
Key takeaways: Strengthening configuration management (CM-02, CM-04, CM-08) for AI
CM-02 (Baseline configuration): Expand baseline configurations to include the full AI stack, including machine learning frameworks, model architectures, data pipelines, and specialized compute environments.
CM-04 (Impact analysis): Update change management processes to evaluate how configuration changes to ML frameworks, libraries, containers, or data pipelines could affect model behavior, accuracy, bias, or drift.
CM-08 (System component inventory): Extend system inventories to track model versions, training data relationships, and dynamically provisioned infrastructure components associated with AI systems.
Additional NIST 800-53 controls to consider for AI systems
Beyond these three families, several additional controls warrant consideration as AI systems scale.
Vulnerability monitoring RA-05
This control must extend to AI-specific components and environments, including:
Machine learning frameworks
Specialized libraries that update frequently
Dynamic compute resources
Model artifacts
Vulnerability scanning should occur at system deployment, after significant model or pipeline changes, and at regular risk-based intervals.
Malicious code protection under SI-03(08)
Implementing SI-03(08) in AI environments requires accounting for unauthorized commands targeting model access points. Data ingest methods should parse inputs to block system-level commands, much the way SQL injection protections work in traditional applications.
Threat modeling under SA-11(02)
Finally, implementation of SA-11(02) should also evolve to track the threats that affect AI deployments. This includes monitoring vulnerabilities associated with the model itself, the datasets used for training, and the development tools used to build and deploy AI systems.
Practical takeaways for security leaders
The work ahead is not about creating entirely new security frameworks. It is about adapting proven (and implemented) controls to address the realities of autonomous systems operating within your environment.
The NIST SP 800-53 catalog already contains the controls you need. Now is the time to apply them with the specificity that AI and agentic systems demand.
1. Start with visibility
For CISOs and security teams, the first and most actionable steps begin with visibility.
Map how agentic systems traverse your environment: what boundaries they cross, what data they access, and what changes they initiate. Security teams should build identity and access management practices that treat agents as first-class entities, assigning unique identities and granular, lifecycle-aware permissions.
Invest in observability infrastructure capable of handling the volume and complexity of agent-generated audit data, capturing not just what happened but the decision chain that led to each action.
2. Expand control coverage across the AI lifecycle
Configuration management practices must also evolve.
Expand your configuration management scope to include the full AI stack, treating model artifacts, training pipelines, and ML frameworks with the same rigor applied to traditional infrastructure components. Impact analysis processes should evaluate how changes affect model behavior, not just security and availability.
It is also critical to recognize that AI access patterns change across lifecycle phases. The permissions an agent requires during model training differ from those needed in production environments, and your controls should reflect those differences.
The Bottom Line
Organizations that begin adapting their NIST SP 800-53 implementation now, and particularly around access control, audit, and configuration management, will be better positioned as regulatory expectations around AI security continue to mature.
Teleport features for AI compliance with NIST SP 800-53
Teleport supports NIST SP 800-53 compliance for AI environments by establishing a unified layer across humans, machines, workloads, and agentic systems. Identities are secured cryptographically using short-lived certificates that generate context-rich, identity-traceable, and audit-ready logs.
This includes support for many of the NIST 800-53 controls discussed in this article:
Referenced NIST SP 800-53 control
Example Teleport features for AI compliance
AU-03: Content of audit records
Identity-traceable audit logs, Kubernetes request-level logging, and full session recordings for human and non-humans
AU-04: Audit log storage capacity
Audit log streaming to S3 and DynamoDB to accommodate increases in log volume due to autonomous activity
AU-10: Non-repudiation
Session recording, certificate-bound audit logs, and SSO identity attribution for all machines and agents
CM-08: System component inventory
Live inventory of nodes, clusters, databases, and applications
SC-10: Network disconnection
Requires valid X.509 or SSH certificates for connection with session termination upon certificate expiry; session locks; inactivity timeouts
Simplify NIST 800-53 compliance
Teleport is trusted to simplify NIST 800-53 compliance for cloud-native, on-prem, and AI infrastructure across multiple control categories, including:
Securing Agentic AI: Navigating Identity & Access in the Machine Era – Andromeda Security
The AI revolution is moving beyond simple chatbots and entering the era of Agentic AI. Businesses are rapidly adopting AI agents that can act independently or on behalf of human users to solve complex problems and drive efficiency.
But with this innovation comes a critical question: How do we secure them? Over the last few months, we have met with more than 100 CISOs, security leaders, and Identity and Access Management (IAM) leaders to gather their perspectives on Agentic AI security. The consensus is clear: organizations are struggling to keep up, and security teams are deeply concerned about the risks posed by the rapid adoption of AI agents across business units.
The 4 Major Security Challenges of Agentic AI
Security leaders consistently pointed to four major hurdles they need to overcome to gain control::
Visibility and “Shadow AI”: Organizations don’t know how many agents are currently being used. Questions remain about who the active users are, what use cases they serve, and where these agents are created—whether on personal devices, dedicated agent platforms, or elsewhere.
Business Risk and Data Leakage: What applications, resources, and data do these agents have access to? There is a significant concern about data leakage, specifically about how much proprietary enterprise data is being fed into public LLMs. Leaders are looking for ways to block public LLM access and enforce the use of secure enterprise LLMs.
Defining Policy Controls: Security teams need the ability to define strict policy controls—dictating exactly what an agent can access, and conversely, who is authorized to access and use a specific agent.
Detecting Anomalous Behavior: Traditional threat detection is built for humans and standard software. Teams need new ways to monitor and detect anomalous, potentially malicious, agent behavior.
The Two Faces of AI Agents: Deployment Models & Risks
Securing AI agents isn’t a one-size-fits-all endeavor. There are two distinct deployment models for agents, and each comes with entirely different security and policy control requirements:
1. The Autonomous Agent (The Digital Workforce)
These agents perform independent functions. The most common example is an AI support gent that autonomously handles L1 and L2 support cases, only escalating to human L3 agents when necessary.
To function, this agent needs access to case management systems, documentation, and various other applications.
The Security Challenge: A unique service account (Non-Human Identity or NHI) must be created in each application the agent interacts with. It is critical that these NHIs are granted only the required privileges. For example, data write access should be granted only when strictly necessary. Unlike a human user who generally sticks to their workflow, if you grant an AI agent broad access, it will natively explore and try to use all the access it has, which can lead to disastrous outcomes.
2. The On-Behalf Agent (The Co-Worker / Co-Pilot)
In this model, a human user leverages an agent to assist in their daily work. The agent uses the human user’s credentials to access applications such as Salesforce, Snowflake, or Slack. The user logs in, generates OAuth tokens for these apps, and grants them to the agent.
The Security Challenge 1: The “Mirror” Problem (Over-Privilege): Because the agent is acting on behalf of the user, it is technically limited to the scope of that user’s permissions. In theory, this provides clear guardrails. However, in most enterprises, the reality is that human users are drastically over-privileged. While ethical human users generally stick to their established workflows, an AI agent will actively explore the boundaries of those privileges to solve a problem—finding and utilizing “accidental” access that the human may not even know they have.
Security Challenge 2: Credential Persistence & Lifecycle Gap Agents require secrets (NHI keys or API tokens) to maintain these “on-behalf-of” connections. These secrets are often long-lived and manually managed.
The Risk: If these keys are hardcoded or stored in insecure vaults to avoid “breaking” the agent, they become permanent backdoors.
The Lifecycle Problem: When a project ends, or an agent is “retired,” the keys often remain active. Organizations struggle to rotate or revoke these keys because they fear disrupting the agent’s complex logic or causing downtime.
3. The Hybrid Agent (The Multi-Modal Workflow)
In complex enterprise environments, agents often operate in a hybrid capacity, combining autonomous capabilities with delegated human authority to complete end-to-end business processes.
A hybrid agent uses its own NHI identity to access core systems (like a database or CRM) while simultaneously using human tokens to act on behalf of a user in communication or productivity tools (like email or Slack).
The Security Challenge 1: The Identity “Mashup”: Because these agents juggle both their own service accounts and user-delegated tokens, they often fall into a “governance gap.” Security teams struggle to determine if an action was performed by the agent’s core identity or via the user’s delegated session, making it nearly impossible to enforce a consistent security policy or baseline.
The Security Challenge 2: Agentic Cascading: Hybrid agents often trigger “sub-agents” to complete specialized tasks. This creates a chain of delegated authority—acascading effect—where the original human prompt ripples through multiple layers of identities and permissions. If one agent in the chain is compromised or over-privileged, the entire workflow becomes a high-speed conduit for unauthorized data access or lateral movement that is invisible to traditional monitoring tools.
The Path Forward: Securing the Agentic Workforce
To scale safely, security teams must move from “all-or-nothing” access to a dual-track governance model tailored to the agent’s role.
Micro-Entitlements: Replace broad service roles with task-specific access. Agents should only reach the specific APIs and data required for their immediate mission.
Contextual & Threshold Approvals: Implement human-in-the-loop guardrails for high-stakes actions or require the presence of a specific business event (e.g., an open support ticket) to validate the agent’s activity before execution.
Behavioral Guardrails: Establish activity baselines for every agent. If an agent deviates from its mission—such as a support bot suddenly attempting a bulk data export—the action is automatically flagged or blocked, regardless of its assigned permissions.
Automated Key Lifecycle: Automate the rotation, vaulting, and revocation of the NHI keys used for application access. This removes the risk of “forever keys” and prevents manual management from becoming a security backdoor.
Human Accountability: Map every agent to a human owner responsible for its lifecycle. These “digital subordinates” must be included in the owner’s regular access reviews and compliance certifications.
Policy-Based JIT Access: Replace standing access to AI assistants with Just-In-Time (JIT) provisioning. A user’s ability to invoke an agent should be governed dynamically by contextual business policies, such as their current role or active projects.
Scoped Access (Permission Intersection): Prevent the agent from fully mirroring an over-privileged human. Use scoped OAuth 2.0 tokens to restrict the agent to a narrow subset of the user’s permissions, limited only to the requirements of the specific task.
Human-Centric Behavioral Baselines: Establish a baseline by learning a user’s typical behavioral patterns. This is then used to validate agent actions; operations outside the human’s normal pattern are automatically flagged for verification.
Ephemeral Tokens & Session Lifecycle: Eliminate persistent connections to user applications. Utilize short-lived, delegated tokens tied directly to the active session that automatically expire the moment the interaction concludes.
Chained Identity Auditing: Maintain strict forensic visibility. Ensure audit logs clearly distinguish between an action performed manually by a human and an action executed by an agent acting on their behalf.
3. Hybrid Agents: Governing the “Identity Mashup”
Unified Identity Mapping: Maintain a consolidated view of activity, linking actions taken via the agent’s NHI and delegated human tokens as a single, cohesive event.
Downstream Propagation Limits: Prevent “Cascading” risks by enforcing strict depth limits on agent-to-agent delegation, ensuring sub-agents cannot inherit more permissions than the primary agent.
Cross-Context Audit Trails: Capture the entire “chain of command” in logs, allowing security teams to trace a sub-agent’s action back through the hybrid agent to the original human intent.
Introduction: The Year “Vibe Coding” Broke the Dam
For the software industry, 2025 was the year the floodgates gave way. The meteoric rise of generative AI transformed “vibe coding” from a niche experimental curiosity into a mainstream industrial force, effectively collapsing the traditional barriers to entry for software creation. But this democratization of development came with a staggering, compounding price tag: 28.65 million new hardcoded secrets detected in public GitHub commits in a single year.
This is not a cumulative tally; it represents the sheer volume of new API keys, passwords, and certificates exposed in 2025 alone. It marks a 34% increase from the previous year—the largest single-year jump ever recorded by GitGuardian. While AI has granted us the power to build at a velocity previously unimaginable, it has simultaneously hallucinated a sense of security, creating a massive “identity debt” that most organizations are ill-equipped to pay. As we dive into the State of Secrets Sprawl 2026, it is clear that our creation velocity has officially outpaced our governance maturity.
The AI Infrastructure Leak Trap
The most striking trend in our latest data is the explosion of AI-related credentials, which surged by 81.5% year-over-year. As organizations rush to deploy “agentic AI” and complex RAG (Retrieval-Augmented Generation) architectures, the “AI stack” is becoming a primary source of algorithmic sprawl.
The risk, however, is not evenly distributed. While the core LLM providers (OpenAI, Anthropic) are relatively well-monitored, the surrounding infrastructure is leaking 5x faster. This “Infrastructure Leak Trap” is fueled by the complexity of connecting disparate services. We are seeing unprecedented surges in leaks for retrieval APIs and orchestration tools: Brave Search (+1,255%), Firecrawl (+796%), and Perplexity (+657%) have become high-growth hotspots for credential exposure.
Furthermore, as new providers emerge, there is an inevitable lag before security protections catch up. A prime example is DeepSeek, where we detected 113,000 new API keys in 2025. This arms race between new AI services and security guardrails ensures that 8 of the top 10 fastest-growing types of leaked secrets are now tied directly to the AI ecosystem.
“8 of the top 10 fastest-growing types of leaked secrets YoY are tied to AI services.”
The “Claude Code” Penalty: AI Assistants are 2x More Likely to Leak
In 2025, the “AI penalty” became a measurable reality for engineering teams. Specifically, commits co-authored by Anthropic’s Claude Code leaked secrets at a rate of 3.2%, more than double the human-only baseline of 1.5%.
This elevated risk profile is driven by a distinctive “AI-generated change set” profile. Claude Code-assisted commits are consistently larger, often containing 2x the number of lines as human-only commits. This sheer volume of code provides more surface area for credentials to slip through. At its peak in August 2025, Claude Code-assisted commits reached 31 secrets per 1,000 commits—roughly 2.4x the human baseline.
The turning point only arrived in late September 2025 with the release of Claude Sonnet 4.5. This update triggered a downward trend in leak rates toward the human baseline, yet the underlying risk remains: the “human in the loop” is still the critical failure point. Developers under pressure often override safety suggestions or explicitly prompt AI to include sensitive information in local configurations for “speed.”
The Immortal Secret: Why 64% of Leaks Never Die
A leaked secret is not a short-lived mistake; it is a durable access path. Perhaps the most alarming finding in our four-year lookback is that 64% of valid secrets leaked in 2022 are still valid and exploitable today.
This “lifecycle negligence” proves that detection is only the first step. The real-world stakes were highlighted by the Shai-Hulud 2 supply chain attack, which revealed that secrets aren’t just lingering on developer laptops—they are embedded in the heart of our infrastructure. The attack found that 59% of compromised machines were CI/CD runners rather than personal workstations. When a secret leaks into build infrastructure, it grants attackers the ability to manipulate workflows and move laterally across the entire software supply chain. Until revocation and rotation become automated and routine, we are essentially leaving the keys to the kingdom in plain sight for years at a time.
“Until revocation and rotation become routine, owned, and automated, a leaked secret is not a short-lived mistake. It is a durable access path that can sit in plain sight for years.”
The Private Repo Fallacy: Why Your Internal Perimeter is a Sieve
There is a dangerous, prevailing myth that internal repositories are “safe” because they are hidden from the public. The data reveals this to be a total mirage: internal repositories are 6x more likely to contain secrets than public ones (32.2% vs. 5.6%).
Privacy is not a security control. Because developers feel a false sense of security within private systems, they are significantly more likely to hardcode high-value, “production-ready” credentials. This complacency extends beyond the codebase. 28% of incidents now originate entirely outside of code repositories—in Slack, Jira, and Confluence. Critically, these non-code leaks are 13% more likely to be categorized as critical than those found in code, creating a massive, unmonitored blind spot for executives who believe their security perimeter ends at GitHub.
MCP: The New Frontier of Exposed Credentials
The Model Context Protocol (MCP) emerged in 2025 as the standard for connecting LLMs to external data. However, the rush to adopt it led to a “normalization” of hardcoding; we detected 24,008 unique secrets exposed in MCP configuration files in its first year.
This sprawl is often encouraged by official documentation that suggests passing API keys as CLI arguments or storing them in JSON config files. The danger of this centralized exposure was illustrated by the Smithery.ai vulnerability, where a single path-traversal bug in an MCP registry exposed overprivileged tokens, granting arbitrary code execution across 3,000+ hosted servers.
To mitigate these risks in agentic workflows, organizations must adopt these best practices:
Use Environment Variables: Never store secrets in MCP config files; use a dedicated secrets manager.
Client Ownership: Clients, not servers, should own credentials and provide them at query time.
Human-in-the-Loop: Require manual approval for any MCP action touching production systems or deployment pipelines.
Version Control Exclusion: Strictly exclude MCP configuration directories from version control via .gitignore.
Conclusion: Is Your Creation Velocity Outpacing Your Identity Maturity?
The central challenge of the AI era is the widening gap between software creation and identity governance. AI is exponentially accelerating the creation of software, but it is not accelerating the governance of the Non-Human Identities (NHIs) that power it.
We are living in a world of “Identity Debt,” where service accounts, API keys, and agent tokens are created in seconds but persist for years. Organizations must move from a reactive posture—asking “Where are my leaked secrets?”—to a strategic one of NHI Governance. You must be able to answer:
What non-human identities exist in my environment?
Who owns them?
What data or resources can they actually access?
If your organization cannot answer these questions, your AI adoption is currently outpacing your security posture. The goal for 2026 is not just finding leaks; it is achieving identity maturity in an ecosystem built by machines.
#1 Authority in NHI Education, Research and Advisory, empowering organizations to tackle the critical risks posed by Non-Human Identities (NHIs), including AI Agents.