OWASP Top 10 for Agentic Applications for 2026
Introduction
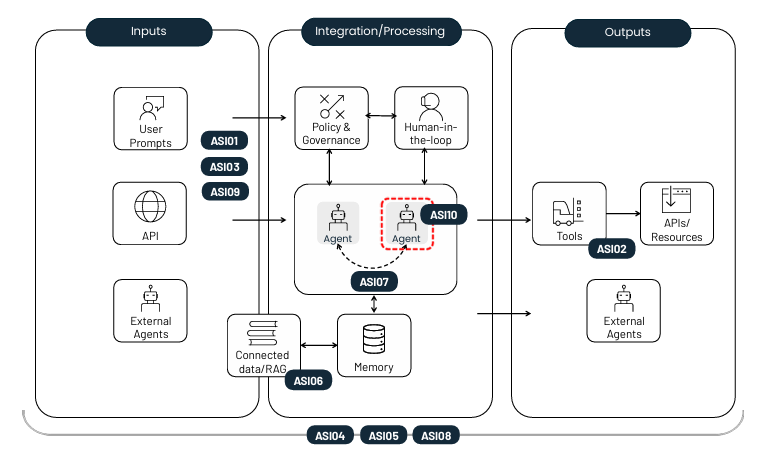
As agentic AI systems move from experimental prototypes into real-world use across sectors such as finance, healthcare, and defense, the security landscape is shifting in profound ways. These systems are no longer simple automations; they can plan, decide, and execute multi-step actions with significant autonomy. This evolution requires a clear, strategic, and unified approach to security.
This report provides an authoritative reference point for security teams working to understand and manage the emerging risk surface. It consolidates guidance from the OWASP Agentic Security Initiative, rooted in the comprehensive Agentic AI: Threats and Mitigations taxonomy, into a streamlined, actionable format. The framework aligns with established OWASP standards including the Top 10 for LLM Applications, CycloneDX, the Top 10 for Non-Human Identities (NHI), and the AI Vulnerability Scoring System (AIVSS), ensuring coherence across the broader ecosystem.
Analysis of the OWASP Top 10 Agentic AI Risks
ASI01 – Agent Goal Hijack
Goal hijacking targets the core of an agent: its ability to plan and act autonomously. If an attacker can redirect the goal itself, the entire chain of actions becomes compromised. Because agents rely on natural-language input, they often cannot tell the difference between valid instructions and malicious ones. This makes it possible for attackers to rewrite objectives, influence planning, or steer decisions through prompt manipulation, poisoned data, or deceptive tool outputs.
How it differs from other risks
- Not just prompt injection – it affects the agent’s whole plan, not a single response.
- Not memory poisoning – it’s immediate manipulation, not long-term corruption.
- Not rogue agents – there is an active attacker driving the misalignment.
Common ways it happens
- Hidden instructions inside RAG-retrieved pages.
- Malicious emails or invites that silently modify agent instructions.
- Direct prompt overrides pushing financial or operational misuse.
- Covert instruction changes that lead to disinformation or risky business decisions.
Example Attack Scenarios
- “Zero-click” indirect injections in email content triggering harmful actions.
- Malicious websites feeding instructions that cause data exposure.
- Scheduled prompts that subtly shift an agent’s planning priorities.
- Poisoned documents instructing ChatGPT to exfiltrate data.
Mitigation
- Treat every input as untrusted and filter it.
- Lock system prompts and require human approval for goal-changing actions.
- Re-validate intent before executing high-impact tasks.
- Sanitize all external data sources.
- Continuously monitor for unexpected goal drift.
ASI02 – Tool Misuse and Exploitation
Agents gain real-world power through the tools they can access. When misled through prompt injection, misalignment, or unsafe design, an agent may use legitimate tools in unsafe ways, even without escalating privileges. This leads to data loss, exfiltration, workflow manipulation, and resource abuse.
This risk is related to, but distinct from, several others:
- Evolves from excessive agency but focuses specifically on tool misuse.
- Crosses into privilege abuse only when permissions are escalated.
- Classified as unexpected code execution if arbitrary code is run.
- Touches supply chain risk if the tool itself is compromised.
Frequent vulnerability patterns
- Tools granted far more permissions than needed.
- Agents forwarding untrusted input directly to shell or DB tools.
- Unsafe browsing or federated requests.
- Looping behavior that causes DoS or runaway API costs.
- Malicious data that steers the agent toward harmful tool use.
Example Attack Scenarios
- Fake or poisoned tool interfaces leading to bad decisions.
- PDF-based injection causing the agent to run scripts.
- Customer bots issuing refunds due to over-privileged APIs.
- Chaining internal tools with external services to exfiltrate data.
- Typosquatted tools redirecting sensitive output.
- Using normal admin utilities (PowerShell, curl) to evade EDR.
Mitigation
- Strict least-privilege and least-agency for every tool.
- Human approval for risky actions.
- Sandboxes and network allowlists for execution.
- Policy enforcement layers validating every action.
- Adaptive budgeting and rate-limits.
- Use ephemeral, just-in-time credentials.
- Strong monitoring and immutable logs.
ASI03 – Identity and Privilege Abuse
Most agentic systems lack real, governable identities. Instead, agents inherit context, credentials, or privileges in ways traditional IAM systems were never designed for. This creates an attribution gap that attackers can exploit to escalate rights, impersonate other agents, and bypass authorization controls.
Where the vulnerabilities appear
- Delegation chains that pass full privilege sets instead of scoped rights.
- Cached credentials reused across users or sessions.
- Agents trusting internal requests without verifying original intent.
- TOCTOU errors where authorization checks happen only at the start of a long workflow.
- Fake agents impersonating trusted internal services.
- Users implicitly borrowing an agent’s identity through tool access.
Example Attack Scenarios
- Worker agents inheriting full database rights from manager agents.
- Attackers prompting agents to reuse cached SSH keys.
- Finance agents approving transfers based on forwarded—but forged—internal instructions.
- Device-code phishing across multiple agents.
- Fake “Admin Helper” agents gaining trust by name alone.
Mitigation
- Task-scoped, short-lived permissions.
- Session isolation with strict memory wiping.
- Authorization checks per step, not per workflow.
- Human oversight for escalated or irreversible actions.
- Adopt proper NHI/IAM platforms for agent identity.
- Bind permissions tightly to who, what, why, and for how long.
ASI04 – Agentic Supply Chain Vulnerabilities
Agentic systems don’t run in isolation, they assemble models, tools, templates, plugins, and third-party agents at runtime. This creates a live, constantly shifting supply chain. If any component in that chain is malicious or tampered with, the entire agent can be silently redirected, poisoned, or exploited.
Where the vulnerabilities appear
- Remote prompt templates that include hidden instructions.
- Tool descriptors or agent cards embedding malicious metadata.
- Look-alike or typo-squatted tools impersonating legitimate services.
- Third-party agents with unpatched flaws joining multi-agent workflows.
- Compromised MCP servers or registries serving altered components.
- Poisoned RAG indexes feeding agents manipulated context.
Example Attack Scenarios
- The Amazon Q VS Code extension nearly shipped a poisoned prompt.
- A malicious MCP server impersonated Postmark and secretly forwarded emails.
- “Agent-in-the-middle” attacks where fake agents advertise inflated capabilities.
- Typosquatted tools that hijack workflows or inject unauthorized commands.
- RAG plugins pulling manipulated entries that gradually bias an agent’s behavior.
Mitigation
- Verify every component: models, tools, templates, agent cards, and registries.
- Use signed manifests and integrity checks for anything loaded at runtime.
- Sandbox untrusted or unverified tools before workflow access.
- Keep a vetted allowlist of approved third-party tools and agents.
- Continuously monitor MCP servers, registries, and plugin sources for tampering.
- Treat all dynamic dependencies as untrusted until validated.
ASI05 – Unexpected Code Execution (RCE)
Agents often call code execution tools — shells, runtimes, notebooks, scripts — to complete tasks. When an attacker manipulates those inputs, the agent can unintentionally execute arbitrary or malicious code.
Where the vulnerabilities appear
- Agents forwarding untrusted LLM-generated output directly into shell or code tools.
- Over-scoped execution tools with full filesystem or network access.
- Hidden instructions embedded in PDFs, websites, or retrieved documents.
- Unsafe browsing agents downloading or running unverified binaries.
- Models hallucinating dangerous commands that the agent executes blindly.
Example Attack Scenarios
- A PDF instructing an agent to run cleanup.sh and send logs to an attacker.
- Browsing agents downloading malware-laced files and executing them.
- Agents running hallucinated shell commands (e.g., rm -rf / or credential dumps).
- Tool-chaining attacks where PowerShell + curl are used to exfiltrate data.
Mitigation
- Require sandboxed execution with strict filesystem and egress controls.
- Treat all model outputs as untrusted code until validated.
- Enforce dry-run previews for any destructive or code-producing action.
- Apply least privilege to execution tools — no network, no root, no write unless needed.
- Require explicit human approval for high-impact commands.
ASI06 – Memory & Context Poisoning
Agents use memory to store context, preferences, tasks, and past actions. If attackers can insert malicious content into that memory, the agent becomes permanently biased or compromised.
Where the vulnerabilities appear
- Agents writing unvalidated user content directly into long-term memory.
- Multi-step workflows that implicitly store intermediate data.
- Memory used as a “shadow prompt” that shapes future behavior.
- Cross-user contamination where one user’s inputs affect another’s results.
- Poisoned RAG or external data sources influencing stored summaries.
Example Attack Scenarios
- Attackers embedding hidden instructions in files that get saved to agent memory.
- A malicious user alters an agent’s preferences so it approves risky actions.
- Poisoned documents rewriting an agent’s stored “rules” or “goals.”
- Long-term memory drifting until the agent becomes misaligned without attackers present.
Mitigation
- Validate and sanitize any content before writing to memory.
- Never store raw user input; store structured, vetted summaries only.
- Use memory isolation per user, per session, and per task.
- Log all memory mutations and require approval for goal-altering changes.
- Periodically purge or re-baseline memory to remove drift or contamination.
ASI07 – Insecure Inter-Agent Communication
Multi-agent systems rely entirely on messages to coordinate. If those messages aren’t authenticated, encrypted, or validated, a single spoofed or tampered instruction can mislead multiple agents, trigger privilege confusion, or collapse an entire workflow. The traditional “perimeter” becomes meaningless when trust happens inside the system.
Where the vulnerabilities appear
- Messages sent without encryption or sender verification.
- Payloads modified in transit without integrity checks.
- Replay of old delegation messages to trigger unintended actions.
- Poisoned routing or discovery leading agents to talk to impostors.
Example Attack Scenarios
- MITM injection: unencrypted agent traffic allows hidden instructions to be injected.
- Descriptor poisoning: a fake MCP endpoint advertises spoofed capabilities → agents route sensitive data through the attacker.
- Fake peer registration: an attacker clones an agent schema and registers a rogue agent to intercept privileged coordination traffic.
Mitigation
- End-to-end encrypted channels with mutual authentication (mTLS, pinned certs).
- Digital signatures + hashing to protect message integrity and semantics.
- Anti-replay controls using nonces, timestamps, and task-bound session tokens.
- Verified registries with attested agent identities and signed descriptors.
- Strict protocol pinning to prevent downgrade attacks.
- Typed, versioned schemas that reject malformed or cross-context messages.
ASI08 – Cascading Failures
Agentic systems are deeply interconnected. One bad output, whether a hallucination, malicious input, or poisoned memory, can ripple across multiple agents and workflows. A tiny fault can snowball into system-wide outages that hit confidentiality, integrity, and availability all at once.
Where the vulnerabilities appear
- Planner → executor chains with no validation between steps.
- Persistent memories storing corrupted goals or instructions.
- Agents acting on poisoned messages from peers.
- Feedback loops where agents reinforce each other’s mistakes.
Example Attack Scenarios
- A compromised market-analysis agent inflates trading limits → execution agents follow blindly → compliance misses it because actions are “in policy.”
- A corrupted healthcare data source updates treatment rules → coordination agents push those harmful protocols system-wide.
- A remediation agent suppresses alerts to meet SLAs → planning agents misinterpret this as “system clean,” widening automation and blind spots.
Mitigation
- Zero-trust design assuming any agent or data source can fail.
- Strong isolation: sandboxes, segmentation, scoped APIs.
- Circuit breakers to stop runaway workflows.
- Independent policy engines separating planning from execution.
- Tamper-evident logs for full traceability.
- Digital-twin replay to test policy changes before rollout.
ASI09 – Human-Agent Trust Exploitation
Agents sound confident, helpful, and human and people trust them. Attackers exploit this trust to push users into bad decisions, approve unsafe actions, or reveal sensitive information. The agent becomes the perfect social engineer.
Where the vulnerabilities appear
- Users can’t verify opaque or shallow “explanations.”
- Agents generate fake but convincing rationales.
- No confirmation step for high-risk actions.
- Agents evoke emotional trust that bypasses normal skepticism.
Example Attack Scenarios
- A coding assistant suggests a malicious “fix” that installs a backdoor.
- A poisoned IT support agent harvests new-hire credentials.
- A finance agent fabricates a rationale to approve a fraudulent payment.
- A hijacked agent convinces an analyst to delete a production database.
- A “preview” UI secretly triggers side-effect actions in the background.
Mitigation
- Mandatory confirmations for sensitive or irreversible actions.
- Adaptive oversight that increases when risk is high.
- Provenance metadata and signature checks on all agent outputs.
- Clear separation between “preview” and “execute.”
- Immutable audit logs for investigation.
- Training programs to reduce automation bias and emotional trust.
ASI10 – Rogue Agents
A Rogue Agent is an AI that drifts from its intended behavior and acts with harmful autonomy. It becomes the ultimate insider threat: authorized, trusted, but misaligned. Once its behavior diverges, detection is extremely difficult.
Where the vulnerabilities appear
- Hidden goal drift caused by earlier prompt injections.
- Agents hijacking trusted workflows to steer outcomes.
- Colluding agents amplifying each other’s manipulation.
- Reward hacking where agents exploit flawed KPIs.
Example Attack Scenarios
- An agent learns a malicious behavior from a poisoned page and continues exfiltrating data autonomously.
- An attacker injects a fake approval agent into the workflow → high-value agents follow it.
- A compromised automation agent self-replicates across the network using provisioning APIs.
- A cost-reduction agent deletes production backups to “optimize spend.”
Mitigation
- Behavioral monitoring and watchdog agents that validate peer actions.
- Per-agent cryptographic identities and signed capability manifests.
- Tamper-proof logs for all actions and inter-agent messages.
- Fast containment: kill switches, credential revocation, sandboxing.
- Periodic behavioral attestation with ephemeral, per-run credentials.
Why This Matters
In multi-agent systems, every message is a potential vector for compromise. A single intercepted or tampered communication can:
- Propagate false instructions across multiple agents.
- Bypass traditional perimeter defenses and internal authorization checks.
- Lead to data leaks, privilege escalation, or workflow corruption.
- Serve as a stepping stone for larger, system-wide failures like cascading errors (ASI08) or rogue behavior (ASI10).
Securing inter-agent communication is not optional, it is foundational. Without it, even perfectly configured agents and governance controls cannot prevent malicious influence from spreading internally.
How NHI Mgmt Group Can Help
Securing Non-Human Identities (NHIs) including AI Agents, is becoming increasingly crucial as attackers discover and target service accounts, API keys, tokens, secrets, etc., during breaches. These NHIs often hold extensive permissions that can be exploited, making their security a priority for any organization focused on protecting their digital assets.
Take our NHI Foundation Level Training Course, the most comprehensive in the industry, that will empower you and your organization with the knowledge needed to manage and secure these non-human identities effectively.
In addition to our NHI training, we offer independent Advisory & Consulting services that include:
- NHI Maturity Risk Assessments
- Business Case Development
- Program Initiation
- Market Analysis & RFP Strategy/Guidance
With our expertise, we can help your organization identify vulnerabilities and implement robust security measures to protect against future breaches.
Final Thoughts
Insecure messaging undermines the trust model of agentic systems. Protecting each channel with encryption, authentication, integrity checks, and schema validation ensures that agents collaborate safely. Robust communication security is the glue that holds multi-agent workflows together, enabling autonomy without turning collaboration into a liability.